又到周五晚上自由时间,^_^。今天看了一下 Node.js。
服务器端 JS 情缘
在校期间我学会了JavaScript和Java,当时我就在考虑JS有没有类似JSP一样的服务器端程序,名字应该是JSSP(JavaScript Server Page),可以在 HTML 中嵌入 JS。Google了一圈发现IIS支持用JScript代替VBScript做ASP开发,另外SourceForge上真有个叫JSSP的项目,以及今天的主角Node.js。当时的Node.js刚起步,首页背景还是黑乎乎的(不晓得其他童鞋是否也有印象)。经过一圈比较,我最终选择使用Rhino——一个纯Java实现的JS引擎,它吸引我的地方是能直接调用Java类库。
Node.js
最近关注Node.js人变多了。在长期与一堆厚重的Java框架、类库为伍之后,我也想看看外面的世界。Node.js最为人所津津乐道的就是异步加回调机制以及良好的性能。我想知道它和我熟悉的Java有何不同。
Node.js 要解决的问题
在使用Java开发的过程里,经常会有与下面类似的代码:
// block A
// do something
// block B
// on Database
ResultSet rs = dbo.executeQuery("Query Statement");
while (rs.next()) {
// block C
// parse the result
}
// block D
// do something
代码块A先处理一些任务;代码块B发送查询语句到数据库,等待返回数据集;代码块C处理返回结果;代码块D继续做其他事情。执行时序图如下:
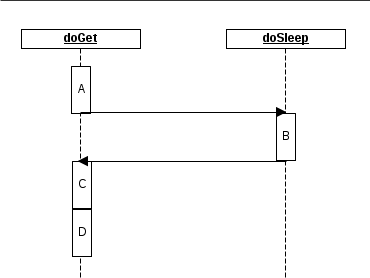
容易看出,在等待代码块B时,整个程序都暂停了,中间有一大段空闲时间没有处理任何任务。从依赖关系上说,代码块C必须在代码块B成功执行后才能执行;但代码块D对前面的B、C并没有依赖关系。因此,如果在等待期间先执行代码块D,直到代码块B执行完毕再触发代码块C。如下图所示:
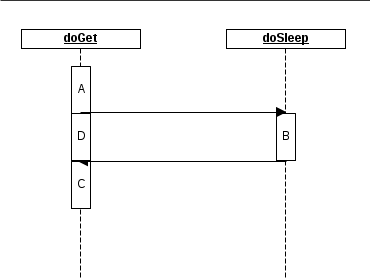
假设每个代码块所需的执行时间是5秒,那第一种方案需要20秒,而第二种只需要15秒。Node.js要做的事情就是使用第二种方案取代第一种方案以获得性能的提升。
回调函数队列
情理之中意料之外,Node.js实现的方式是单进程且单线程。它内部维护着一个回调函数队列,遵循先到先处理的原则逐个执行。让我联想到批处理操作系统,任务一个接一个地执行,没有抢占并享有所有系统资源。Node.js回调机制所做的事情就是把相应的代码块塞到队尾。
比如上一节的例子中的方法二,执行过程就变成:代码块A被塞到队列中;数据库查询语句注册了一个事件并绑定代码块C为回调函数;代码块D被塞到队尾;此时代码块B执行完成并触发事件,把代码块C塞到队尾。因此,依次执行的是A、D、C(注:B是数据库服务器上的查询操作,并不是Node.js中执行的代码),期间并无间歇。
考虑下面的代码,就遵循上述的代码模式:
- 代码块A:请求计数以及记录请求开始处理的时间(不是到达时间)。
- 代码块B:此处用setTimeout做了5秒延迟,模拟外部程序处理五秒钟。
- 代码块C:记录回调函数被调用的时间,睡5秒来模拟服务器运算,并记录结束时间。
- 代码块D:记录响应的时间(即用户收到回馈的时间)。
var http = require('http');
var count = 0;
http.createServer(function(request, response) {
// block A
count++;
var id = count;
var start = new Date();
var reply;
// block B
setTimeout(function() {
// block C
var called = new Date();
var end;
do {
end = new Date();
} while (end.getTime() - called.getTime() < 5000);
console.log(id + ' start @ ' + start);
console.log(id + ' reply @ ' + reply);
console.log(id + ' called @ ' + called);
console.log(id + ' end @ ' + end);
}, 5000);
// block D
response.writeHead(200, {'Content-Type': 'text/html'});
response.end();
reply = new Date();
}).listen(80);
在我的机器上执行结果如下:
λ sudo node main.js
1 start @ Fri Sep 21 2012 19:12:35 GMT+0800 (CST)
1 reply @ Fri Sep 21 2012 19:12:35 GMT+0800 (CST)
1 called @ Fri Sep 21 2012 19:12:40 GMT+0800 (CST)
1 end @ Fri Sep 21 2012 19:12:45 GMT+0800 (CST)
和预期的一样:请求在19:12:35时开始处理,并且没有被阻塞,而是在同一时间就返回了;5秒后回调函数开始被处理;又过了5秒回调函数执行完毕,整个过程结束。
我们来数数上面这段代码总共有几个显眼的回调函数:
- 整段代码/文件是一个回调函数,在程序启动时被塞到队列中并立即执行了;
- createServer 中注册的回调函数,在收到用户请求后被触发(塞到队列,不一定马上执行);
- setTimeout 中注册的回调函数,在延迟5后才被塞到队列。
单线程的问题
Node.js采用单进程+单线程的其中一个原因是避免系统频繁开辟线程带来的开销。网络上说开启一个线程要使用2M的内存(有这么多?),我没去验证过具体数值,但至少是有一些开销的,当请求量大是的确会成为瓶颈。上节提到Node.js的处理任务的方式类似批处理操作系统,因此它在规避线程开销的同时也完全继承了批处理方式的缺陷——交互不友好。我指的交互是后面的请求会被回调函数队列中前面的任务阻塞住,从接受到回馈耗费很长的时间等待。
用下面代码分别在第0秒、第1秒、第7秒发送一个请求,并记录每个请求从发出到收到回馈的时间:
#!/bin/bash
date
time curl http://localhost
sleep 1
date
time curl http://localhost
sleep 6
date
time curl http://localhost
date
执行结果如下:
- 19:16:36 发送第一个请求,几乎马上收到回馈;
- 等待1秒后发送第二个请求,同样马上收到回馈;
- 继续等待6秒发送第三个请求,耗时8秒后猜收到回馈!
$ ./submit.sh
2012年 09月 21日 星期五 19:16:36 CST
real 0m0.018s
user 0m0.004s
sys 0m0.008s
2012年 09月 21日 星期五 19:16:37 CST
real 0m0.015s
user 0m0.012s
sys 0m0.000s
2012年 09月 21日 星期五 19:16:43 CST
real 0m7.982s
user 0m0.000s
sys 0m0.004s
2012年 09月 21日 星期五 19:16:51 CST
相信第三次请求的用户会极其不满,来看看Node.js执行时的快照:
1 start @ Fri Sep 21 2012 19:16:36 GMT+0800 (CST)
1 reply @ Fri Sep 21 2012 19:16:36 GMT+0800 (CST)
1 called @ Fri Sep 21 2012 19:16:41 GMT+0800 (CST)
1 end @ Fri Sep 21 2012 19:16:46 GMT+0800 (CST)
2 start @ Fri Sep 21 2012 19:16:37 GMT+0800 (CST)
2 reply @ Fri Sep 21 2012 19:16:37 GMT+0800 (CST)
2 called @ Fri Sep 21 2012 19:16:46 GMT+0800 (CST)
2 end @ Fri Sep 21 2012 19:16:51 GMT+0800 (CST)
3 start @ Fri Sep 21 2012 19:16:51 GMT+0800 (CST)
3 reply @ Fri Sep 21 2012 19:16:51 GMT+0800 (CST)
3 called @ Fri Sep 21 2012 19:16:56 GMT+0800 (CST)
3 end @ Fri Sep 21 2012 19:17:01 GMT+0800 (CST)
下表中A1表示第一次请求中的代码块A,其他以此类推。假定代码块A、B、D都是瞬间完成,只有C耗时5秒。从表中可知,第三次请求是在第15钟才开始被处理。根据测试脚本的输出可知,第三次请求其实在第7秒就已经发出了,但由于是那时队列中还有C1、C2在处理,因此等待了8秒钟!假设队列的平均长度是100,那每个请求平均的等待时间就是 (100 / 4 - 1) * (A+B+C+D),即要等前面24个请求处理完。这还仅仅是请求得到回馈的时间,该请求对应回调函数被执行的时间还要更久。
| 当前时间 | 当前队列 |
| 0 | A1 B1 D1 |
| 1 | A2 B2 D1 |
| 5 | C1 |
| 6 | C1 C2 |
| 7 | C1 C2 A3 B3 D3 |
| 10 | C2 A3 B3 D3 |
| 15 | A3 B3 D3 |
| 20 | C3 |
| 25 |
适用场景
通过上面的研究,我觉得Node.js并不适合需要与用户实时交互的系统;它适合集中处理用户发来的大规模“指令”,即不需要及时看到结果的请求。比如微博系统,用户发表一条微博,可能需要在服务器上排队1分钟才能最终保存到数据库。在这一分钟里,用户更多地是看看别人发表的微博,并不十分迫切地想看到自己那条微博。如果希望有更好的体验,其实可以用DOM直接把用户发表的微博先更新到当前页面,同时使用Ajax异步请求保存这条数据。